Grafana 대시보드 구축
메트릭 수집은 Observability의 절반에 불과하다. 나머지 절반은 시각화다. 데이터가 쌓여도 볼 수 없으면 의미가 없다.
LGTM 스택을 구축했지만 대시보드가 없었다. 커뮤니티 대시보드를 import 해봤지만 우리 환경과 맞지 않았다. 결국 운영 관점에서 필요한 대시보드를 직접 설계하고 구축했다. GitOps로 대시보드를 관리하는 방식도 함께 정리한다.
운영 관점에서 세 가지가 필요했다.
- 인프라 대시보드: 클러스터 전체 상태, 노드 헬스, 리소스 사용량
- APM 대시보드: 서비스별 요청량, 에러율, 레이턴시
- 파이프라인 대시보드: LGTM 스택 자체의 헬스 체크
Datadog을 쓸 때는 기본 제공되던 것들이다. LGTM 스택에서는 직접 구성해야 한다.
클러스터 전체 상태를 한눈에 파악하기 위한 대시보드다.
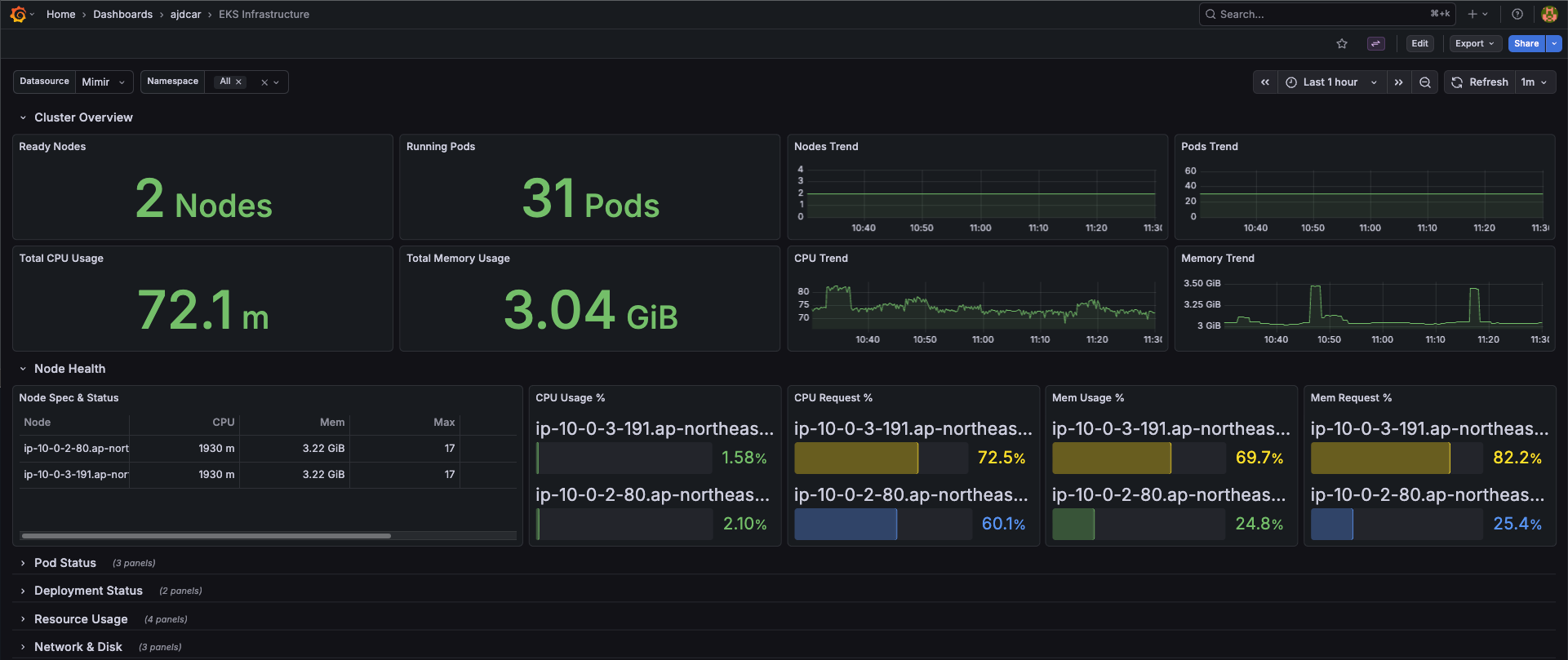
대시보드를 열었을 때 3초 안에 “지금 클러스터가 정상인가?“를 판단할 수 있어야 했다.
상단에는 핵심 숫자를 배치했다:
- Ready Nodes / Running Pods → 클러스터가 살아있는가
- Total CPU / Memory → 전체 리소스 현황
- Trend 그래프 → 급격한 변화가 있는가
그 아래로 드릴다운 할 수 있도록 섹션을 구성했다:
| 섹션 | 확인 포인트 |
|---|---|
| Node Health | 특정 노드에 문제가 있는가 |
| Pod Status | Pending, Failed Pod가 있는가 |
| Deployment Status | Replica가 부족한 Deployment가 있는가 |
| Resource Usage | 리소스를 과도하게 사용하는 컨테이너가 있는가 |
노드 상태 확인:
|
|
CPU 사용률 (노드별):
|
|
서비스별 트래픽과 성능을 모니터링하는 대시보드다.

“지금 서비스에 문제가 있는가?“를 빠르게 파악하는 것이 목적이다.
RED 메트릭(Rate, Errors, Duration)을 기준으로 구성했다:
- Rate: 요청량 추이, 평소 대비 급증/급감 확인
- Errors: 에러 발생 현황, 4xx/5xx 구분
- Duration: 레이턴시 분포, p50/p95/p99 확인
Version Timeline 패널은 배포 시점을 표시한다. 성능 저하가 발생했을 때 “최근 배포 때문인가?“를 바로 확인할 수 있다.
요청량:
|
|
p95 레이턴시:
|
|
에러율:
|
|
LGTM 스택 자체를 모니터링하는 대시보드다. 수집기(Alloy)와 저장소(Loki, Mimir, Tempo) 컴포넌트의 헬스를 확인한다.
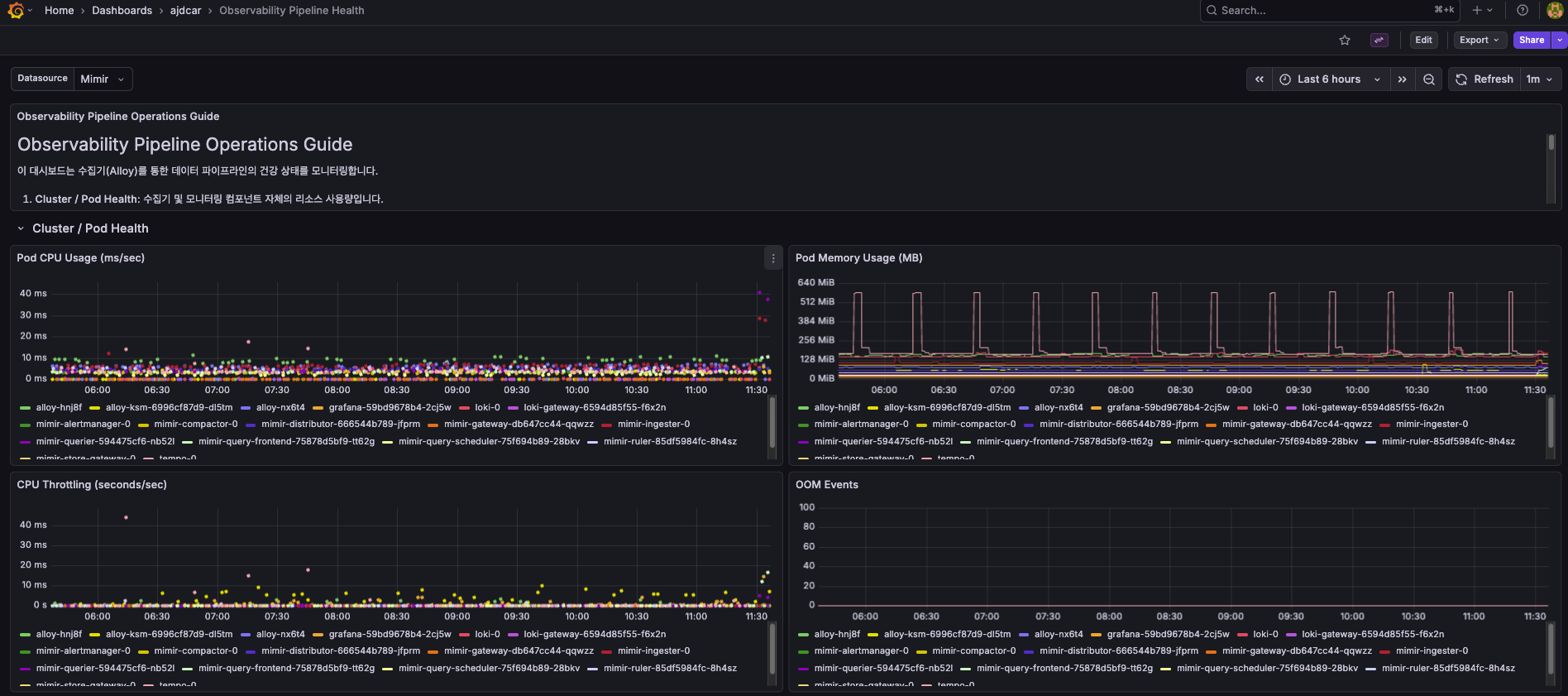
모니터링 시스템이 죽으면 알림도 오지 않는다. LGTM 스택 자체의 상태를 별도로 감시해야 한다.
주요 확인 포인트:
- Pod CPU/Memory Usage: 각 컴포넌트의 리소스 사용량
- CPU Throttling: 리소스 limit에 걸려서 throttling 되는지
- OOM Events: 메모리 부족으로 재시작되는 Pod가 있는지
Mimir Ingester나 Loki가 OOM으로 재시작되면 메트릭/로그 유실이 발생할 수 있다. 이 대시보드로 사전에 감지한다.
대시보드에 패널이 많아지면 로딩이 느려진다. 처음엔 Row를 기본 접힘(collapsed) 상태로 설정해서 필요한 섹션만 펼쳐보는 방식을 고민했다.
찾아보니 Grafana는 기본적으로 lazy loading을 지원한다. 뷰포트에 보이는 패널만 쿼리를 실행하고, 스크롤하면 그때 로딩한다. 덕분에 Row를 굳이 접어두지 않아도 초기 로딩이 무겁지 않았다.
다만 상단 Overview 섹션은 항상 펼쳐두고, 세부 섹션은 필요에 따라 Row collapse를 활용했다.
대시보드를 UI에서만 관리하면 변경 이력 추적이 안 된다. 누가 언제 뭘 바꿨는지 알 수 없고, 롤백도 어렵다.
대시보드 JSON을 Git에 저장하고, Grafana ConfigMap provisioning으로 자동 배포하는 방식을 선택했다.
|
|
워크플로우:
- Grafana UI에서 대시보드 수정
- JSON export
- Git commit & push
- Helm upgrade 또는 Pod 재시작 시 자동 반영
이렇게 하면 대시보드도 코드처럼 리뷰하고 관리할 수 있다.
대시보드 JSON 파일은 Git으로 관리한다.
observability/grafana/dashboard/
├── eks-infrastructure-dashboard.json
├── app-api-dashboard.json
└── observability-dashboard.json
ConfigMap 프로비저닝을 설정해두면 Grafana Pod 재시작 시 자동으로 로드된다. 대시보드가 코드로 관리되니 변경 이력 추적도 가능하다.
대시보드를 만들고 나니 모니터링이 실체화되었다. 알림이 오면 대시보드를 열어 상황을 파악하고, 어디를 더 봐야 하는지 판단할 수 있게 되었다.
아직 부족한 부분도 있다. 로그와 트레이스 연동, 더 세분화된 서비스별 대시보드는 다음 단계로 남겨두었다.