EKS 1.32 → 1.33 업그레이드 실전 가이드
EKS 1.33이 릴리스됐다. 보통 마이너 버전 업그레이드는 “Control Plane 올리고, Addon 올리고, Node 올리면 끝"이라고 생각하기 쉽다. 나도 그렇게 생각했다.
dev 환경에서 먼저 작업하면서 예상치 못한 문제들을 만났다. VPC CNI 설정 불일치로 Pod IP 할당이 안 되고, Karpenter CRD 버전 문제로 노드 프로비저닝이 막히고, Datadog DD_HOSTNAME 누락으로 모니터링이 깨졌다.
dev에서 삽질한 덕분에 prod는 40분 만에 깔끔하게 끝냈다. 그 과정을 공유한다.
| 환경 | 노드 구성 | 특이사항 |
|---|---|---|
| dev | MNG + Karpenter | Self-managed Addons |
| prod | MNG + Karpenter | Self-managed Addons |
두 환경 모두 Self-managed Addon 방식이다. EKS managed addon이 아니라 직접 이미지 버전을 관리한다. 이게 업그레이드 시 추가 작업이 필요한 이유다.
|
|
약 8분 소요. 여기까지는 순조로웠다.
Self-managed addon이라 직접 이미지를 업데이트해야 한다.
|
|
VPC CNI 업데이트 후 테스트 Pod를 띄워봤다.
|
|
Pod가 Pending 상태에서 멈췄다. VPC CNI 비정상으로 aws-node DaemonSet이 실패하면서 노드가 NotReady 상태가 되어 스케줄링 자체가 안 됐다.
NAME READY STATUS RESTARTS AGE IP NODE
test-pod 0/1 Pending 0 30s <none> <none>
원인을 파헤쳐보니 Network Policy 설정이 불일치했다.
|
|
ConfigMap에서는 Network Policy를 끄라고 하고, DaemonSet env에서는 standard 모드로 켜라고 한다. VPC CNI가 혼란에 빠진 것이다.
해결:
|
|
이후 aws-node Pod가 재시작되면서 정상화됐다.
|
|
|
|
에러가 났다.
An error occurred (InvalidParameterException) when calling the UpdateNodegroupVersion operation:
Nodegroup can't be upgraded because maxSize (2) is equal to desiredSize (2).
Surge 업그레이드 방식이 막힌 것이다. EKS는 노드 그룹 업그레이드 시 새 노드를 먼저 띄우고 기존 노드를 드레인하는 Surge 방식을 쓴다. 그런데 maxSize가 desiredSize와 같으면 새 노드를 띄울 공간이 없다.
해결:
|
|
Karpenter 노드는 EC2NodeClass의 AMI Selector를 변경하면 Drift가 감지되어 자동으로 교체된다.
|
|
그런데 노드가 안 뜬다. Karpenter 로그를 확인했다.
|
|
ERROR controller.provisioner unable to determine if instance type
"t3.medium" is allowed by the NodePool, error: unsupported nodeClassRef
kind, no corresponding implementation found, expected one of
[]schema.GroupVersionKind{schema.GroupVersionKind{...}}
Karpenter CRD 버전 문제였다. Karpenter v1.0.5에서 v1.5.0으로 업그레이드하면서 CRD가 변경됐는데, Helm 업그레이드 시 CRD가 자동으로 업데이트되지 않았다.
해결:
|
|
이후 AMI Selector 변경이 정상 반영되고 노드가 교체됐다.
업그레이드 후 Datadog 대시보드를 확인하는데 일부 노드에서 호스트 메트릭이 누락됐다.
원인: Datadog Agent가 DD_HOSTNAME 환경변수 없이 띄워졌다. 기존 노드에서는 설정되어 있었는데, 새 노드에서 Agent가 재시작되면서 값이 누락된 것이다.
Helm values를 확인해보니 DD_HOSTNAME이 spec.nodeName에서 가져오도록 설정되어 있지 않았다.
해결 (Terraform에서 Helm values 수정):
|
|
Helm upgrade 후 정상화됐다.
업그레이드 후 Datadog 대시보드를 점검하다가 Pod 리소스 정보(CPU/Memory requests/limits)가 표시되지 않는 걸 발견했다.
Node Agent 로그를 확인해보니 에러가 발생하고 있었다.
|
|
error pulling from collector "kubelet": couldn't fetch "podlist":
unable to unmarshal podlist... decode slice: expect [ or n, but found {
원인: Kubernetes 1.33에서 kubelet API의 allocatedResources 필드 포맷이 배열 []에서 객체 {}로 변경됐다. Datadog Agent 7.64.1은 이전 포맷만 지원해서 파싱에 실패한 것이다.
영향 범위:
| 메트릭 | 상태 |
|---|---|
| container.* (containerd 직접 수집) | 정상 |
| kubernetes.* (kubelet API) | 실패 |
APP 서비스 자체에는 영향 없지만, Datadog에서 Pod CPU/Memory requests/limits 정보를 볼 수 없는 상태였다.
해결:
|
|
--reuse-values 대신 --reset-then-reuse-values를 사용한 이유: 새 chart 버전에서 추가된 설정값(예: dynamicInstrumentationGo.enabled)이 nil이 되면서 template 에러가 발생한다. --reset-then-reuse-values는 새 chart의 기본값을 먼저 적용한 후 기존 커스텀 값을 덮어씌운다.
참고: https://github.com/DataDog/datadog-agent/issues/37501
| 단계 | 예상 | 실제 | 비고 |
|---|---|---|---|
| Control Plane | 10분 | 8분 | 정상 |
| Core Addons | 5분 | 25분 | VPC CNI 설정 불일치 |
| MNG Node Group | 10분 | 15분 | maxSize 문제 |
| Karpenter Nodes | 15분 | 25분 | CRD 버전 문제 |
| 검증 | 5분 | 15분 | DD_HOSTNAME 발견 |
| 총 | 45분 | ~90분 |
dev에서 삽질한 내용을 바탕으로 prod 업그레이드 전에 사전 작업을 진행했다.
| 작업 | 내용 |
|---|---|
| DD_HOSTNAME 설정 | Datadog Helm values 수정 |
| Replicas HA | 핵심 워크로드 replicas 2 이상 확인 |
| PDB 설정 | 핵심 워크로드 PDB 확인 |
| MNG maxSize | maxSize > desiredSize 확보 |
| Karpenter 업그레이드 | v1.0.5 → v1.5.0, CRD 선행 적용 |
| 단계 | 소요 시간 | 누적 |
|---|---|---|
| Pre-check | 1분 | 1분 |
| Control Plane 업그레이드 | 8분 | 9분 |
| VPC CNI env 제거 + Addon 업그레이드 | 5분 | 14분 |
| Pod IP 할당 테스트 | 1분 | 15분 |
| MNG 노드 업그레이드 (Surge) | 9분 | 24분 |
| Karpenter 노드 교체 | 12분 | 36분 |
| 전체 검증 | 5분 | 41분 |
총 41분. dev에서 90분 걸린 것과 비교하면 절반 이하로 줄었다.
| 항목 | dev | prod |
|---|---|---|
| VPC CNI env 제거 | 문제 발생 후 조치 | 업그레이드 전 선제 조치 |
| MNG maxSize | 변경 필요 (2→4) | 이미 충분 (5>3) |
| Karpenter CRD | 문제 발생 후 조치 | 사전에 적용 완료 |
| DD_HOSTNAME | 업그레이드 후 발견 | 사전에 적용 완료 |
dev 경험을 바탕으로 정리한 체크리스트다.
|
|
|
|
|
|
|
|
|
|
|
|
prod에서 40분 만에 끝낼 수 있었던 건 dev에서 모든 문제를 미리 겪었기 때문이다. dev 업그레이드를 “빨리 끝내야 할 작업"이 아니라 “문제를 발견하는 기회"로 봐야 한다.
EKS managed addon이면 버전 호환성을 AWS가 관리해준다. Self-managed는 직접 이미지 버전을 맞춰야 하고, 설정 충돌도 직접 해결해야 한다.
| 사전 작업 | 이유 |
|---|---|
| MNG maxSize 확보 | Surge 업그레이드 가능하게 |
| VPC CNI env 정리 | 설정 충돌 방지 |
| Karpenter CRD 업데이트 | NodeClass 인식 문제 방지 |
| DD_HOSTNAME 설정 | 모니터링 연속성 |
| Replicas/PDB 확인 | 무중단 보장 |
체크리스트를 따라가기만 하면 안 된다. 각 단계에서 “여기서 막히면?“을 시뮬레이션해야 한다.
- MNG 업그레이드 → maxSize가 모자라면?
- VPC CNI 업그레이드 → Pod IP 할당 안 되면?
- Karpenter AMI 변경 → 노드가 안 뜨면?
미리 시뮬레이션하면 문제를 예방할 수 있다.
이번 업그레이드에서 Claude Code를 활용해 사전 점검 대시보드와 실행 런북을 자동 생성했다.
dev에서 발견한 이슈들을 prod 사전 점검에 반영한 대시보드다. 한눈에 BLOCKER/WARNING/INSIGHTS를 파악할 수 있다.
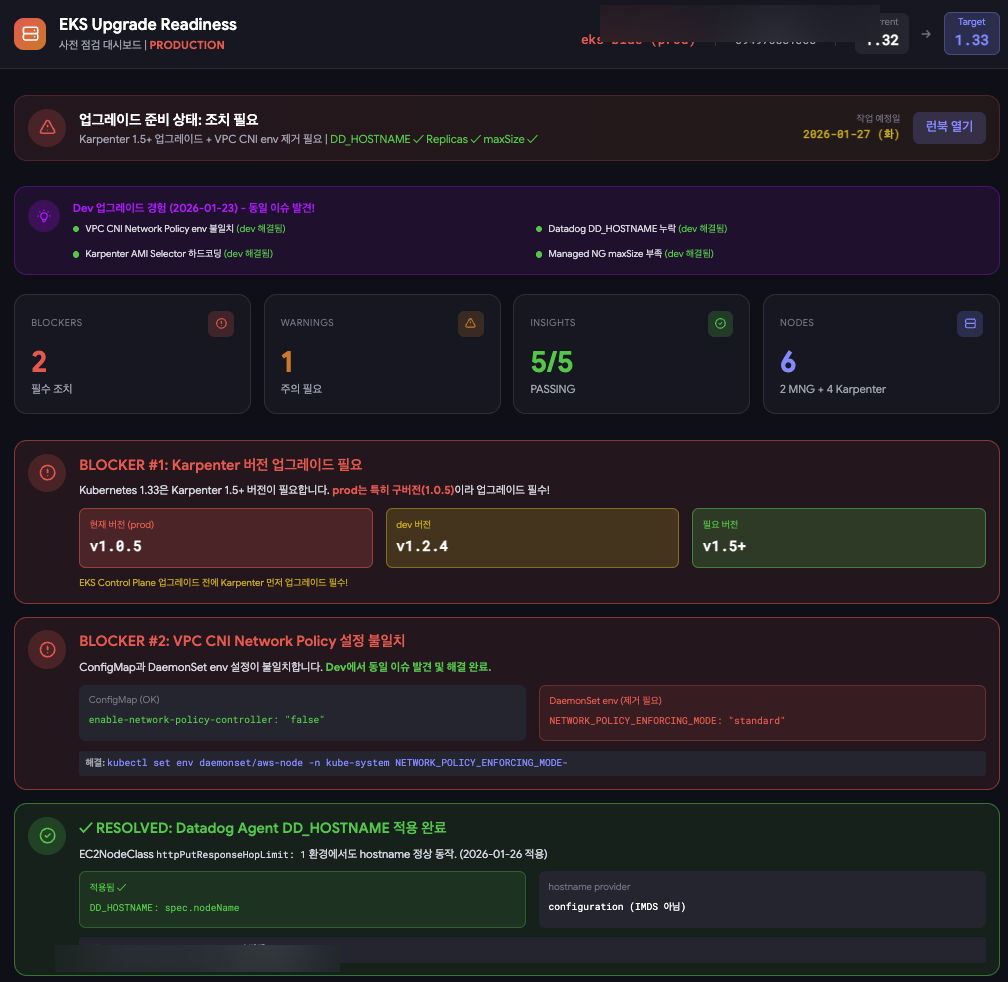
| 섹션 | 내용 |
|---|---|
| BLOCKERS | Karpenter 버전, VPC CNI env 불일치 등 필수 조치 |
| WARNINGS | 주의 필요 항목 |
| INSIGHTS | EKS Upgrade Insights API 결과 |
| Dev 경험 반영 | dev에서 발견한 이슈 → prod 체크 항목으로 |
핵심 기능:
- 클러스터 상태 자동 조회 (AWS CLI, kubectl)
- dev 이슈 → prod BLOCKER로 자동 연결
- 해결 여부 실시간 표시 (검증됨 ✓)
실제 작업 시 따라갈 수 있는 단계별 런북이다. 작업 개요, BLOCKER 사전 작업, 단계별 체크리스트, 롤백 절차가 포함된다.
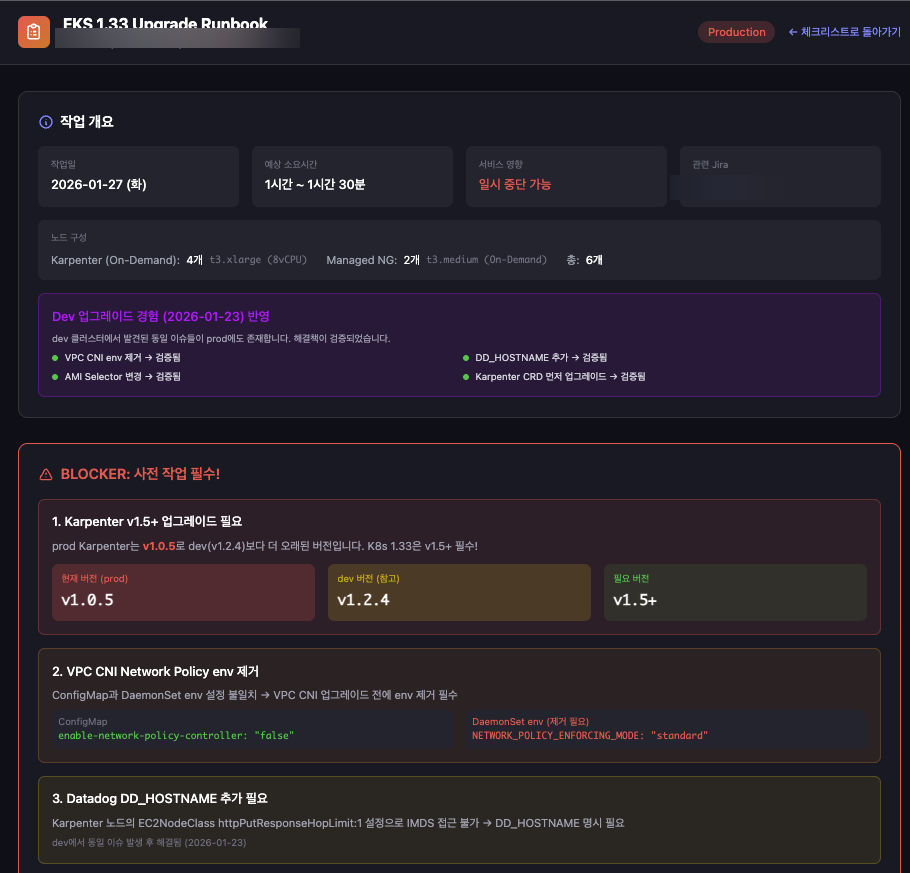
| 섹션 | 내용 |
|---|---|
| 작업 개요 | 날짜, 예상 소요시간, 서비스 영향, Jira 링크 |
| BLOCKER 사전 작업 | dev 경험 기반 필수 선행 작업 |
| 단계별 체크리스트 | Control Plane → Addons → MNG → Karpenter |
| 롤백 절차 | 문제 발생 시 복구 방법 |
활용 방식:
- AI가 클러스터 상태 조회 → 대시보드 생성
- dev 이슈 분석 → BLOCKER 항목 도출
- 런북 생성 → 팀 공유 및 작업 시 참조
prod 업그레이드가 41분 만에 끝난 건 이런 준비 덕분이다. AI를 코드 작성용으로만 쓰지 않고, 운영 지식을 정리하는 도구로 활용해봤다.
최종 버전 (prod):
| 구성요소 | 이전 | 이후 |
|---|---|---|
| Control Plane | 1.32 | 1.33 |
| VPC CNI | v1.19.2 | v1.21.1 |
| CoreDNS | v1.11.4 | v1.12.4 |
| kube-proxy | v1.32.0 | v1.33.0 |
| Node (MNG) | v1.32.3 | v1.33.5 |
| Node (Karpenter) | v1.32.3 | v1.33.5 |
| Karpenter | v1.0.5 | v1.5.0 |
EKS 업그레이드는 단순해 보이지만, Self-managed 환경에서는 숨은 복잡성이 있다. VPC CNI 설정 충돌, Karpenter CRD 호환성, 모니터링 설정 등 예상 못한 곳에서 문제가 생긴다.
dev에서 90분 걸린 작업이 prod에서는 41분에 끝났다. 차이는 사전 준비다. dev에서 발견한 문제들을 대시보드와 런북으로 정리하고, 사전 작업으로 해결해둔 덕분이다.
AI를 활용해서 클러스터 상태 점검, 이슈 정리, 런북 생성까지 자동화한 것도 도움이 됐다. 다음 업그레이드 때도 같은 방식으로 진행할 예정이다.